yolo-v4
一、yolo 背景
one-stage Vs two-stage
one-stage 输入图像 => (x1,y1)和(x2,y2) 一个 CNN 网络提取特征做回归
two-stage 先进行预选,再做预测结果
one-stage 优缺点
优点:快、适合做实时监测任务
缺点:得到的效果相对于 two-stage 不会太好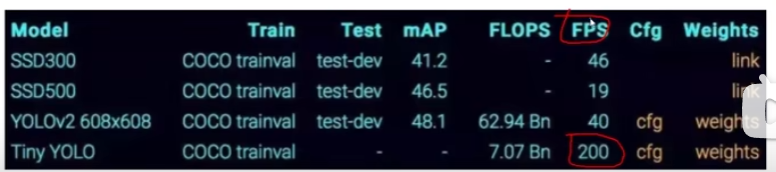
FPS 表速度、mAP 表效果
指标
map 指标
综合衡量检测效果
FN 漏检
检测任务中的精度和 recall 分别代表什么?
基于置信度来计算,例如:分别计算 0.9、0.8、0.7
基于每个阈值计算精度和召回率,如下图
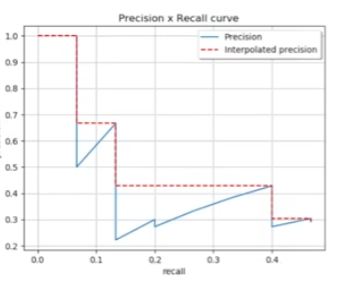
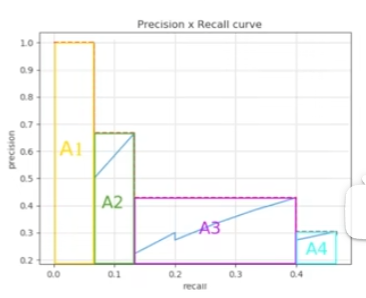
map 值就是图中曲线所围成的面积
IOU 指标
IoU=交集/并集
二、YOLO-V1
把检测问题转换成回归问题,应用于对视频进行实时检测。
核心思想
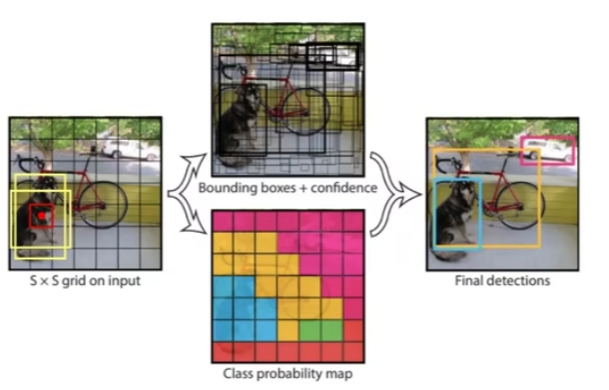
- 输入一个图像,分成 S*S 个格子
- 每个格子产生两种候选框,每个候选框都要和真实物体比对计算 IoU 的值
- 哪个候选框的 IoU 大就对谁做微调
- 最终会生成无数个候选框和置信度(当前点是否为物体)
- 过滤掉置信度小的框,即为最终结果
网络架构
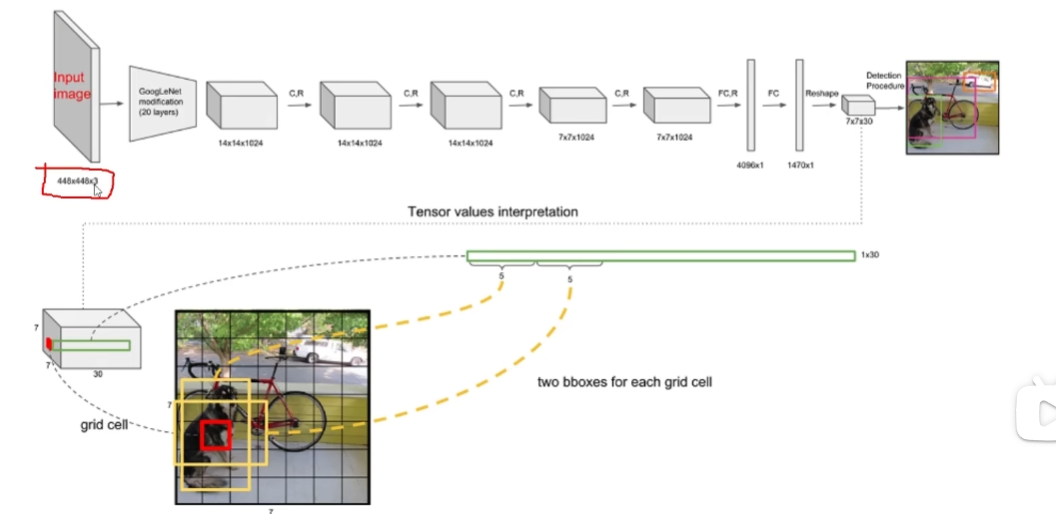
v1 版本输入 448*448 的图片,做了多次卷积(v3 中展开),得到一个特征图:771024。
全连接层:
- 第一个全连接层转为 4096 个特征
- 第二个全连接层转为 1470 个特征=>reshape 后为 7730
- 其中,7*7 代表最终网格大小
- 30=5+5+20 :5 是指预选框的 5 个数值(x,y,w,h,c=置信度),一共有两个框所以是 5+5。
- 20 指的是当前数据集有 20 个类别,指每个格子中判别物体的 20 个概率
损失函数
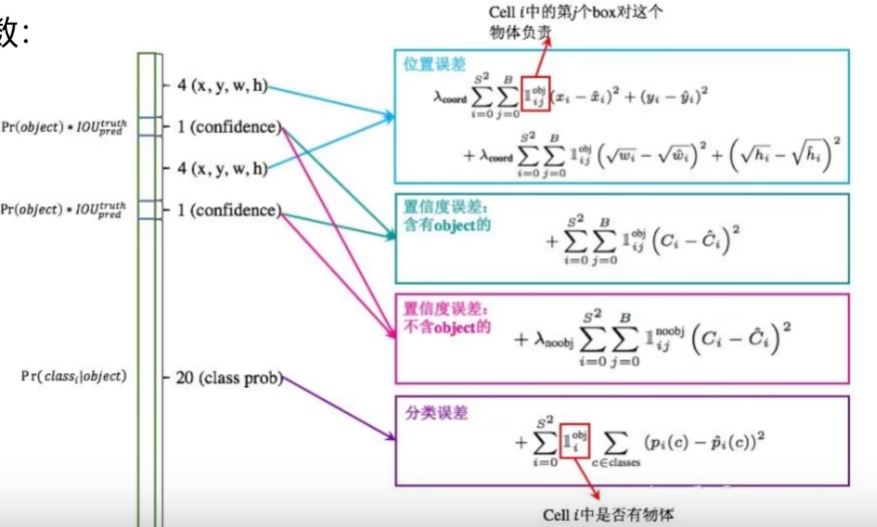
$\sum_{i=0}^{s^2} $ 表示一共有 s*s 个网格
$\sum_{j=0}^B $ 对于每个网格,有两个候选框
$x_i$表示真实值;$\hat{x}$表示预测值。
选择 IoU 最大的预选框计算真实值和预测值之间的差异。
为什么 w、h 要加根号
结合开方函数可知,当自变量 x 数值较小时 y 变化敏感,自变量 x 数值较大时,y 变化不敏感。所以结合模型来看,当框较大时,差值为 1 个单位损失极小;而框小较小,如只有 2*2 的时候,差值为 1,误差就相对更大了。
置信度误差
算候选框和真实值的 IoU,如果>0.5,则认为当前预测的是个前景,置信度为 1。当多个候选框和真实框重叠时,只选 IoU 最大的预选框。
置信度误差分为含有物体和不含物体的。
含有物体时,计算置信度和真实值的差异。
不含物体时,要加一个权重参数。因为一个图片中背景多,样本是不均衡的。如果不加权重项,整个损失函数更多会由背景来影响。
还有一个分类误差。最终加在一起就是整个损失函数。
NMS(非极大值抑制)
NMS 是当检测出多个框重叠时,只选取 IoU 中最大值的框,其他就不要了。
优缺点分析
优点:快速、简单
缺点:
- 每个 cell 只预测一个类别,重合在一起的物体不好检测
- 小物体检测不到,长宽比可选但单一
解决了什么问题
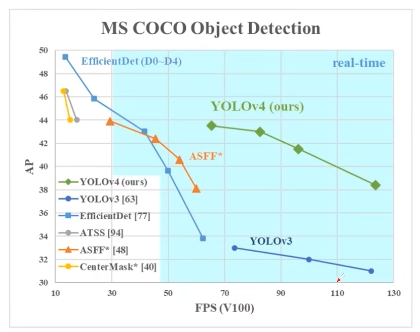
- 开发了一种高效而强大的目标检测模型。 它使每个人都可以使用 1080 Ti 或 2080 Ti GPU 训练超快速和准确的目标检测器。
- 在检测器训练期间,验证了最先进的 Bag-of-Freebies 和 Bag-of-Specials 目标检测方法的影响。
- 我们修改了最先进的方法,使它们更有效,更适合单 GPU 训练,包括 CBN [89],PAN [49],SAM [85]等。
二、YOLO-v2
新特性
对比 v1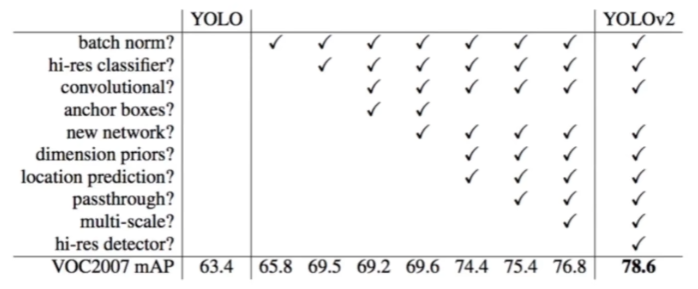
batch normalization
舍弃了 dropout,每一个卷积后加入 batch normalization(drop 一般放在全连接层,防止过拟合)
每一卷积层后加入 normalization,每一层都做归一化,让网络收敛学习起来更容易一些,(已经成为卷积网络的主流做法!!)经过 BN 后的网络会提升 2%的 mAP
更大的分辨率
v1 训练时用的 224*224,测试时用的 448*448;V2 训练时,又进行了 10 次 448*448 的微调。使用了高分辨率的分类器后,v2 的 map 值提升了 4%。
网络结构
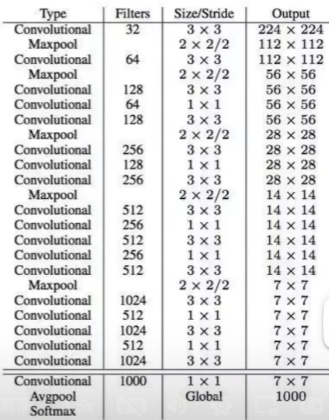
DarkNet-19
网络中去除了所有全连接层,全靠卷积层做,这是因为
- 全连接层容易过拟合
- 全连接层训练慢
实际输入为 416416(可以被 32 整除),做了 5 次降采样,最终输出的宽高为 w=(W/32) h=(H/32),所以最终输出为 1313.
卷积核大小
3*3 的卷积核大小借鉴了 VGG 的思想:用比较小的卷积核做卷积时,更省参数且感受更明显。
1*1 的卷积核只改变了特征图个数,而没有改变其他东西,节省参数。
YOLO-V2-聚类提取先验框
faster-rcnn 系列选择的先验比例都是常规的,但不一定完全适合数据集
K-means 聚类中的距离:
d(box,centroids)=1-IoU(box,centroids)为什么不用欧氏距离?
产生的误差和框的大小正相关,框大产生的误差大,框小误差小,不能正确表示误差。
k 为什么等于 5
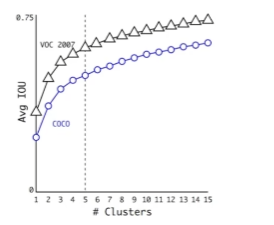
当 k 越大时,每类差异越小,每个类越精确。这里作者做了个折中,当 k>5 时,IOU 的提升没有那么明显了,所以 k=5。有 5 种不同的候选框。
YOLO-V2-Anchor Box
通过引入 anchor boxes,使得预测的 box 数量更多(1313n)
跟 faster-rcnn 不同的四先验框并不是按照长度固定比给定的
YOLO-V2-Directed Location Prediction
直接预测相对位置,预测的不再是偏移量而是相对于 grid cell 的偏移量
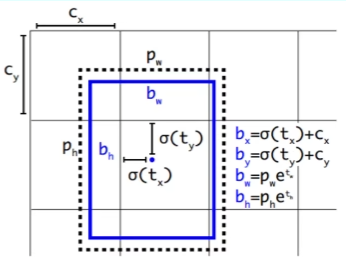
计算公式为:
$$b_x=\sigma(t_x)+c_x$$
$$b_y=\sigma(t_y)+c_y$$
$$b_w=p_we^{t^w}$$
$$b_h=p_he^{t^h}$$
此处
$\sigma$为 sigmoid 函数,将变量限制为 0 到 1 的数。即中心点限制在了一个格子中,不会偏移出去。$c_x$、$c_y$是当前网格在整个画布中的位置。$p_w$、$p_h$是聚类得到的缩放后的候选框的宽高。套用上面的公式计算出结果后,再乘以 32 进行还原。
感受野
概括说就是特征图上的点能看到原始图像多大区域
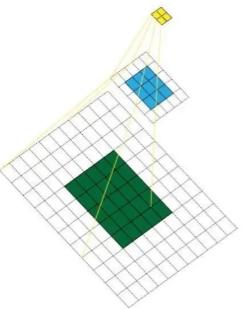
越大的感受野越能感受全局
感受野中卷积核大小的制定
堆叠越小的卷积核所需参数更少,并且卷积过程越多,特征提取更细致,加入的非线性变换也更多,还不会增啊权重参数个数,这就是 VGG 的基本出发点,用更小的卷积核完成特征提取操作。
YOLO-V2-Fine-Grained Features 特征融合改进
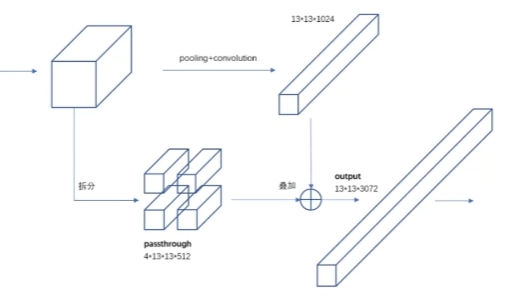
最后一层感受野太大了,小物体可能丢了,需要融合之前的特征。
过程:经过一些卷积之后,不只生成了最后一层特征图、也把前面的特征图进行拆分和拼接;再将拼接好的特征加入最后一层特征图中。
YOLO-V2-Multi-Scale 多尺度检测
实际中的检测图像都是大小不一的,如果都处理成统一的大小,检测效果比较差。因为网络都是卷积操作,每经过一次迭代可以改变输入,让网络具有比较强的适应能力
三、YOLO-v3
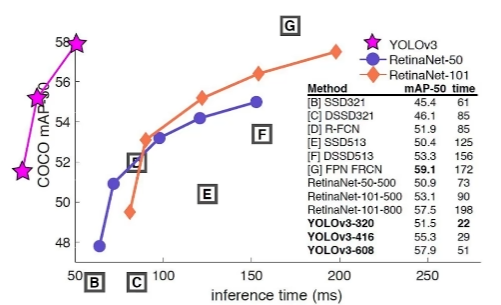
v3 更适合小目标检测,特征更细致;
先验框更丰富,3 个规格,9 种先验框;
softmax 改建,预测多标签任务
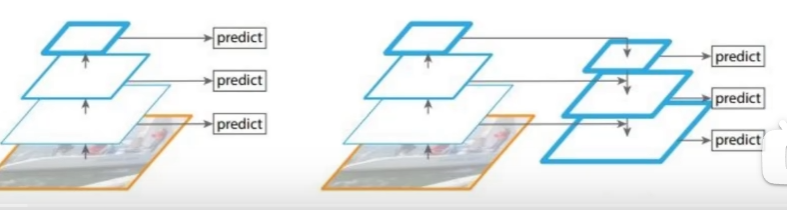
多 scale 方法改进
为了检测不同大小的物体,设计了 3 个 scale,每个 scale 有 3 种候选框。
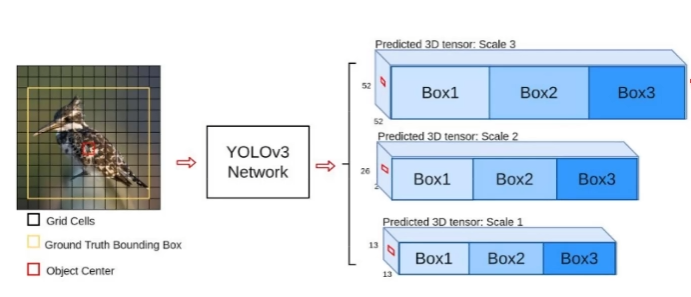
scale 变换经典方法
小目标尺度不匹配的问题采用上采样的方法提取特征后与中目标的特征融合。
核心网络结构
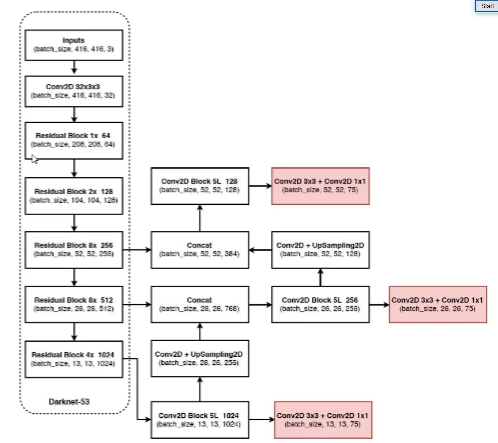
- 没有池化、全连接层
- 下采样通过 stride 为 2 实现,不需要下采样的地方 stride 为 1
- 3 种 scale,更多先验框
- 融入了多种经典做法
将特征图进行上采样+卷积操作(13*13*1024)=> 26*26*256=>进行特征融合(26*26*766)=>卷积特征再提取=>完成最终预测
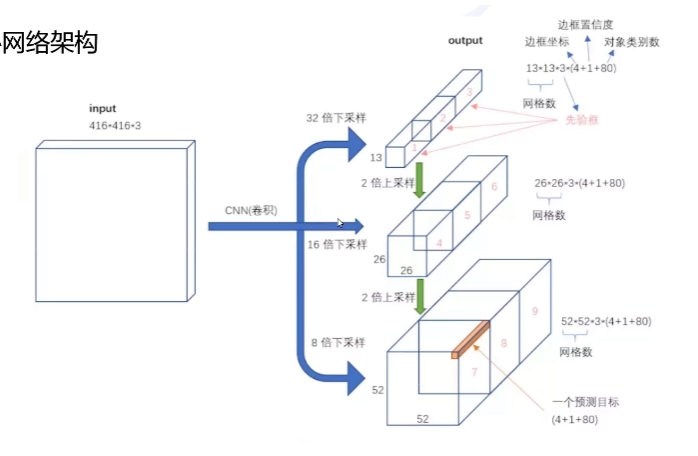
根据不同的特征图,采用不同的先验框

softmax 层改进
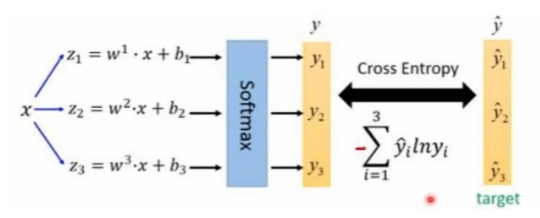
最终的预测结果可能一个物体有多个标签,比如:狗、动物、哈士奇。
用 logistic 激活函数来完成,这样就能预测每一个类别是/不是,把大于阈值的类别筛选出来
四、YOLO-v4
网络结构-CSPDarknet53
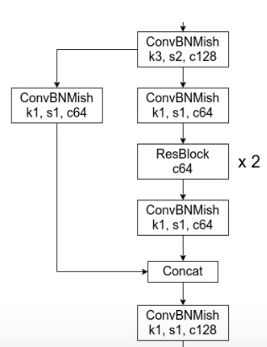
在 yolo 的 darknet53 中引入了 csp 的结构
CSP
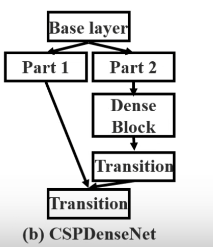
CSP 能够增强 CNN 的学习能力;
移除了计算瓶颈;
减少了存储耗费。
SPP - Spatial Pyramid Pooling
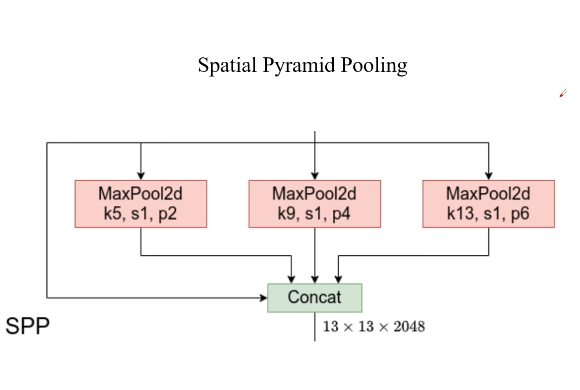
三个最大池化层与下采样层的输入进行拼接,可以在一定程度上解决多尺度的问题
PAN - Path AGGREGATION NETWORK
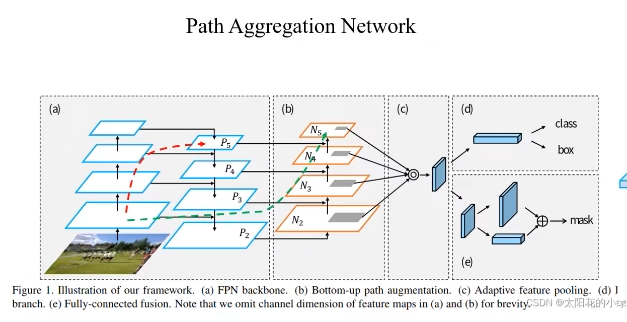
(a)FPN backbone。左边做特征提取,右边做特征金字塔。高层的语义信息往低层融合。
(b)Bootom-up path augmentaion。低层向高层融合。
(a)左边和(b)加在一起就是 PAN。
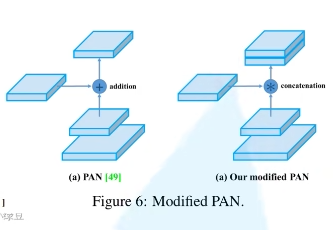
YOLO V4 中修改后的 PAN
优化策略 - Mosaic data augmentation
将四张不同的图片按照一定规则拼接在一起,拼接好后得到一张新的图片,来扩充样本多样性。

应用
二、关联工作
目标检测模型
目标检测模型由以下几部分组成:
Input: Image, Patches, Image Pyramid
Backbones: VGG16 [68], ResNet-50 [26], SpineNet [12], EfficientNet-B0/B7 [75], CSPResNeXt50 [81], CSPDarknet53 [81]
Neck:
Additional blocks: SPP [25], ASPP [5], RFB [47], SAM [85]
Path-aggregation blocks: FPN [44], PAN [49], NAS-FPN [17], Fully-connected FPN, BiFPN [77], ASFF [48], SFAM [98]
Heads:
Dense Prediction (one-stage):
RPN [64], SSD [50], YOLO [61], RetinaNet [45] (anchor based)
CornerNet [37], CenterNet [13], MatrixNet [60], FCOS [78] (anchor free)
Sparse Prediction (two-stage):
Faster R-CNN [64], R-FCN [9], Mask RCNN [23] (anchor based)
RepPoints [87] (anchor free)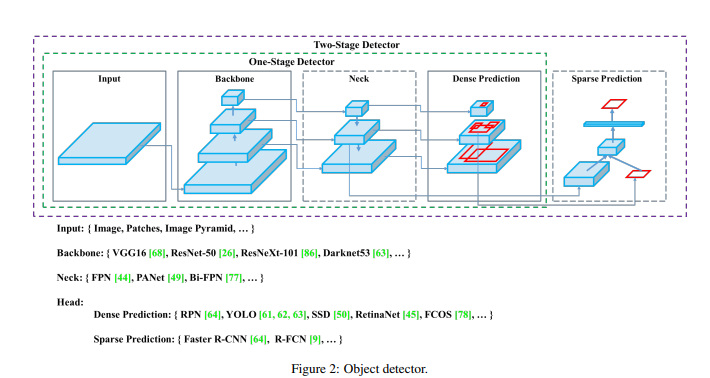
Bag-of-Freebies
我们称这些仅改变训练策略或仅增加训练成本方法为“Bag of freebies ”。
- 数据增强 – pixel-wise
光度失真:图像的亮度、对比度、色调、饱和度和噪声
图像变形:缩放、crop、flip、旋转
reference
论文阅读:YOLOv4,Optimal Speed and Accuracy!
YOLOv4 网络详解