psd纯客户端解析
背景
随着科技的发展和人类审美需求的提高,我们每天都要在电子屏幕上浏览成百上千张图片。这就意味着,作图领域需要高效率的生产工具和工业化流程可以对“原胚”图片进行批量的操作和私人定制。在人力上的分配,设计师只需创造“原胚模板”,使用者只需对“原胚模板”进行表层加工即可。但像 photoshop、sketch、ai 等制图工具,不仅需要相当高的学习成本,还需要完成注册、下载、安装等流程占有比较高额的设备空间和时间成本,这对于仅仅使用“模板”的人并不友好。
而 web 这种无需安装,拿来即用的特性,成为非专业人员进行图像编辑操作的最佳环境。本文讨论的就是在设计人员给出“原胚”,到将其呈现在 web canvas 上的这一过程中,对最经典的 psd 类型文件进行解析的实现进行详述。
为什么在客户端解析?
因为本应用是仅靠客户端的能力将 json 解析为可操作图层,如果是通过服务端进行解析,仍需要把 psd 上传,且因为服务端是 java 写的找不到 psd => json 可用的免费 api 或 sdk,时间成本和开发成本很高,但这也意味着客户端解析时对于用户来说是堵塞的,用户不能关闭界面。在两种方法的权衡下,最终采用了客户端解析,让用户等待。
架构
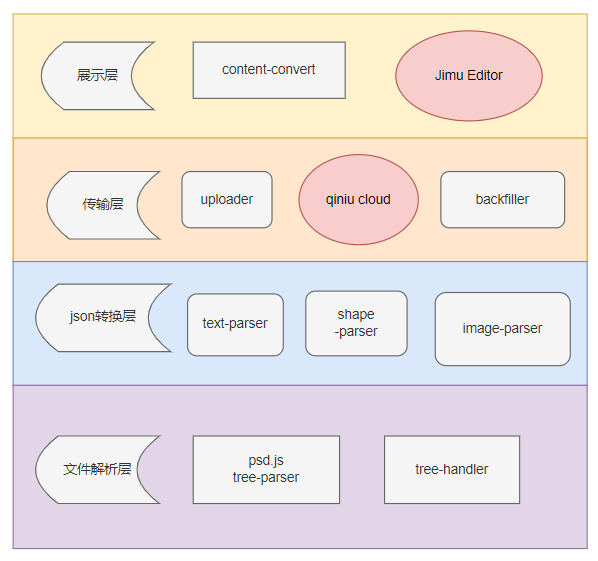
流程
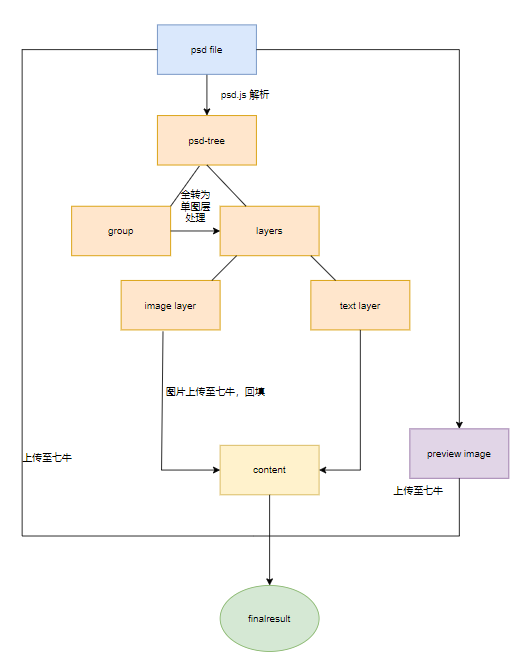
psd file to JSON
本阶段主要使用了psd.js的psd.tree()方法,像官方推荐的export()方法所获取到 psd 的信息非常有限,像图片的内容就获取不到,如下:
{
"children": [
{
"type": "group",
"visible": false,
"opacity": 1,
"blendingMode": "normal",
"name": "Version D",
"left": 0,
"right": 900,
"top": 0,
"bottom": 600,
"height": 600,
"width": 900,
"children": [
{
"type": "layer",
"visible": true,
"opacity": 1,
"blendingMode": "normal",
"name": "Make a change and save.",
"left": 275,
"right": 636,
"top": 435,
"bottom": 466,
"height": 31,
"width": 361,
"mask": {},
"text": {
"value": "Make a change and save.",
"font": {
"name": "HelveticaNeue-Light",
"sizes": [33],
"colors": [[85, 96, 110, 255]],
"alignment": ["center"]
},
"left": 0,
"top": 0,
"right": 0,
"bottom": 0,
"transform": {
"xx": 1,
"xy": 0,
"yx": 0,
"yy": 1,
"tx": 456,
"ty": 459
}
},
"image": {}
}
]
}
],
"document": {
"width": 900,
"height": 600,
"resources": {
"layerComps": [
{ "id": 692243163, "name": "Version A", "capturedInfo": 1 },
{ "id": 725235304, "name": "Version B", "capturedInfo": 1 },
{ "id": 730932877, "name": "Version C", "capturedInfo": 1 }
],
"guides": [],
"slices": []
}
}
}psd tree
所以我们直接去看 psd tree,它是一个树状的结构
进入到_children中,就能看到完整的 psd tree 了。
由于渲染层 editor 的限制,暂时还不支持 group 类型,在拿到 psd tree 后要先进行递归把 tree“铺平”成一个 layer 数组,并赋予唯一标识符,以便在画布上进行相关的图层操作。
parse image
在递归时,由于 psd tree 每个 layer 是统一制式的数据,并没有区分“图像”或“文字”类型。经过多个 psd 数据的验证,发现layer.text不为空与layer.image互斥。这里的判别方式为:观察layer.text是否为空字符串,不为空则为文字类型,反之为图像类型。
image 字段中寸的并非为素材源文件,而是Uint8Array类型的数组,将其转为 base64 后与当前图层的唯一标识符一起存入待上传队列。之后统一上传至七牛云,之后拿到上传后的 key,生成对应的图片链接后,再根据唯一标识符,将图片的链接再回填到 layer 中即可。
parse text
而对于文字图层来说,相比图片图层要更简单,只是处理数据的转换。这里进行了,通道颜色、斜体、下划线、加粗等等。
结果

仍需解决…
- 无法解析蒙版
- shape
- scale 没有解析出来,拉伸后的字体并没有还原